Gabrielle J. Gutierrez, Fred Rieke*, and Eric Shea-Brown*
*co-senior authors
Update: This work is now published in PNAS.
The layered circuitry of the retina compresses and reformats visual inputs before passing them on to the brain. The optic nerve has the channel capacity of an internet connection from the early 90s, yet the brain somehow receives enough information to reconstruct our high-definition world. The goal of this study was to learn something about the compression algorithm of the retina by modeling aspects of its circuit architecture and neural response properties.
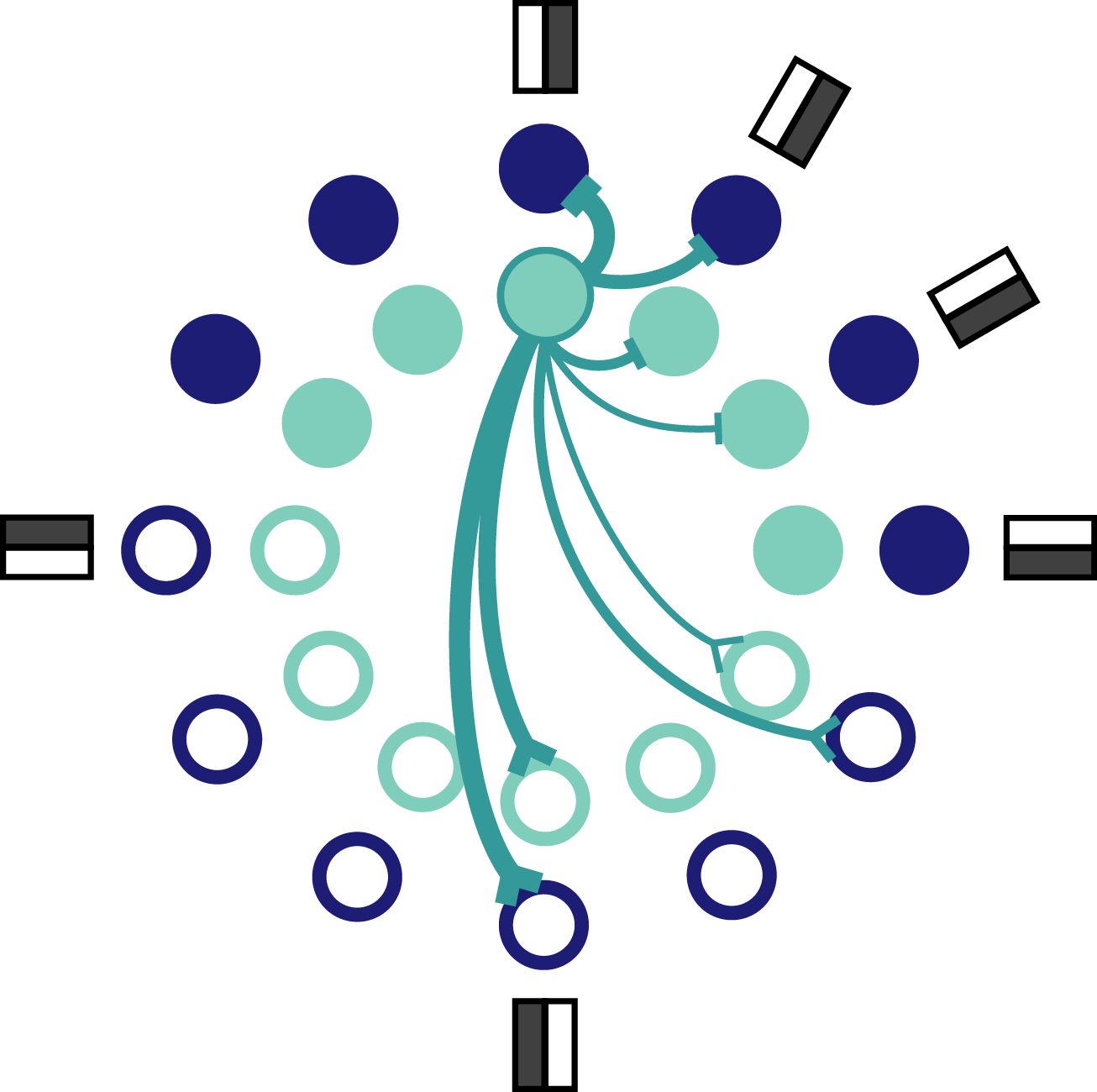
The retina compresses a high-dimensional input into a low-dimensional representation. This is supported by converging and diverging circuit architectures (Fig. 1), along with nonlinear neuron responses. Hundreds of photoreceptors converge to tens of bipolar cells which converge to a single ganglion cell. At the same time, inputs diverge onto many different ganglion cell types that have overlapping receptive fields.

Figure 1: Schematic of retina circuitry illustrating divergence into ON and OFF pathways and convergence within a pathway.
If you look at these circuit components, though, it’s hard to see how they manage to preserve enough information for the brain to work with. For example, converging two inputs can result in ambiguities. In Figure 2, the neural response is simply the sum of the input dimensions. This means that all of the stimuli in the top plot that lie along the orange line are represented by the same response shown by the orange circle in the bottom plot. There’s no telling those stimuli apart, so information is lost by convergence here – down to 12.50 bits in the response from 19.85 bits in the stimulus.

Figure 2: Convergence creates ambiguities, causing information about the stimulus to be lost.
Divergence is another common neural circuit motif. Diverging a stimulus input into two neurons (Fig. 3) expands a 1-dimensional stimulus into a 2-dimensional response but this leads to redundant signals. Here, divergence creates an inefficient neural architecture because it uses two neurons to give you as much information as just one neuron.

Figure 3: Diverging a single inputs into two outputs can produce redundancies.
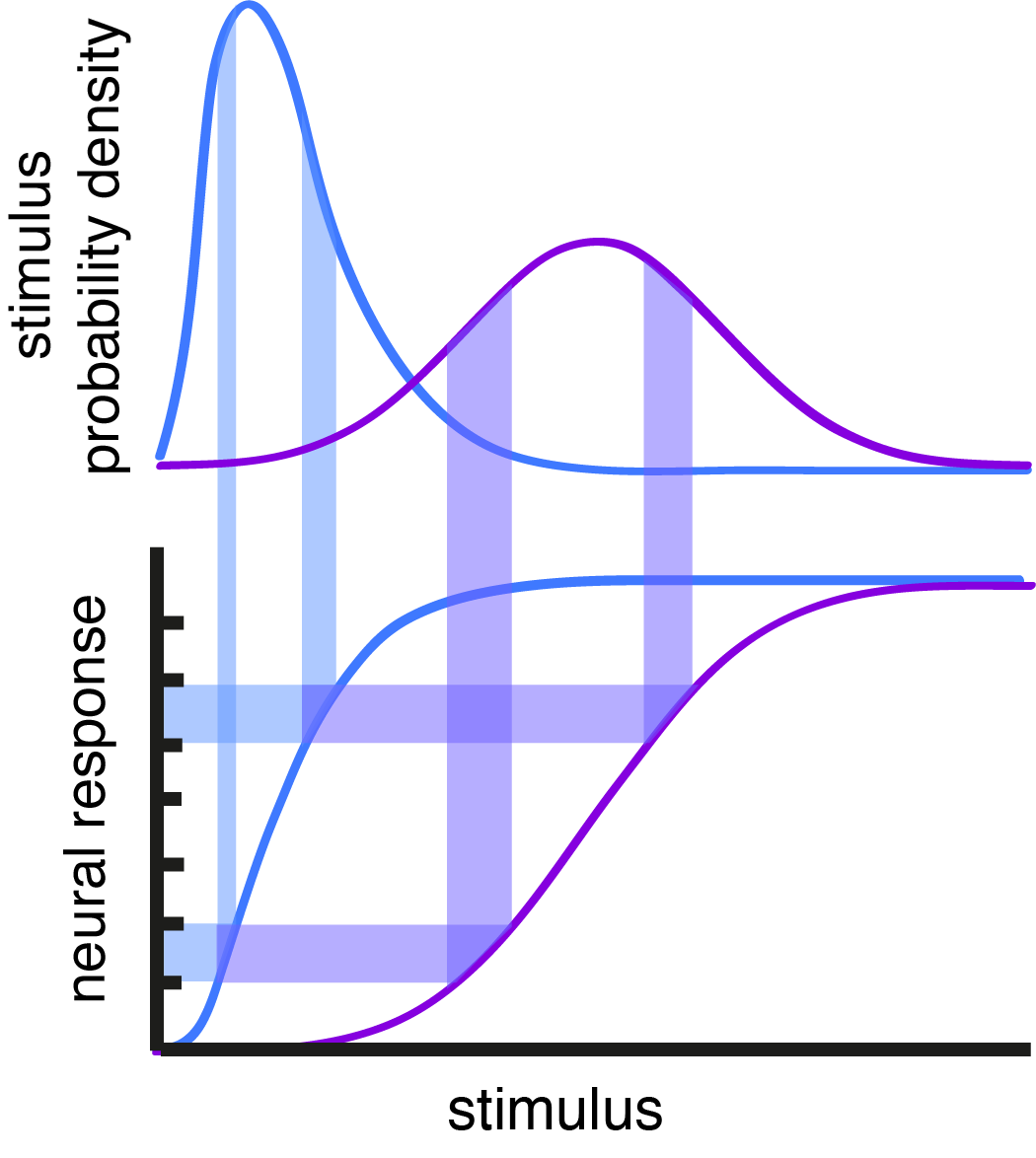
Nonlinear response functions are common in neurons and can make a neuron more efficient at encoding its inputs by spreading its responses around so that information about the stimulus is maximized. Nonlinear response functions can otherwise make a neuron selective to certain stimulus features, but selectivity and efficiency can be in conflict with each other. Figure 4 shows what a rectified linear (ReLU) nonlinearity does to a gaussian stimulus distribution. It compresses the left side of the gaussian so that there is only one response to encode all of the stimuli that fall below the threshold. A lot of information is lost this way. If the stimulus distribution described luminance values in an image, the ReLU would cut out much of the detail from that image.

Figure 4: Nonlinear transformation of a gaussian distributed input with a ReLU can distort the distribution, producing a compressed response where some portion of the stimulus information is discarded.
Given that all of these information-problematic elements make up neural circuits, we wondered: how much information can a compressive neural circuit retain when its neurons are nonlinear? We were surprised to find that a convergent, divergent circuit can preserve more information when its subunits are nonlinear than when its subunits are linear (Fig. 5) – even though the individual linear subunits are lossless and the nonlinear subunits are not.

Figure 5: A convergent, divergent circuit with nonlinear subunits (right) preserves more information about the stimulus than a circuit with linear subunits (left).
To explain this, we’ll start out with a reduced version of the circuit. It has only 2 converging subunits and no divergence. Figure 6 shows how a 2-dimensional stimulus is encoded by each layer of the two circuits being compared. The dark purple band represents stimuli whose two inputs sum to the same value. These stimuli are represented by the same output response in the linear subunits circuit as demonstrated by the dark purple that fills a single histogram bin (left, 3rd and 4th rows). Those same stimuli are represented in a more distributed way for the nonlinear subunits circuit (right, 3rd and 4th rows) – meaning that they are represented more distinctly in the output response.

Figure 6: The encoding of the stimulus space at each circuit layer when the subunits are linear (left) and nonlinear (right).
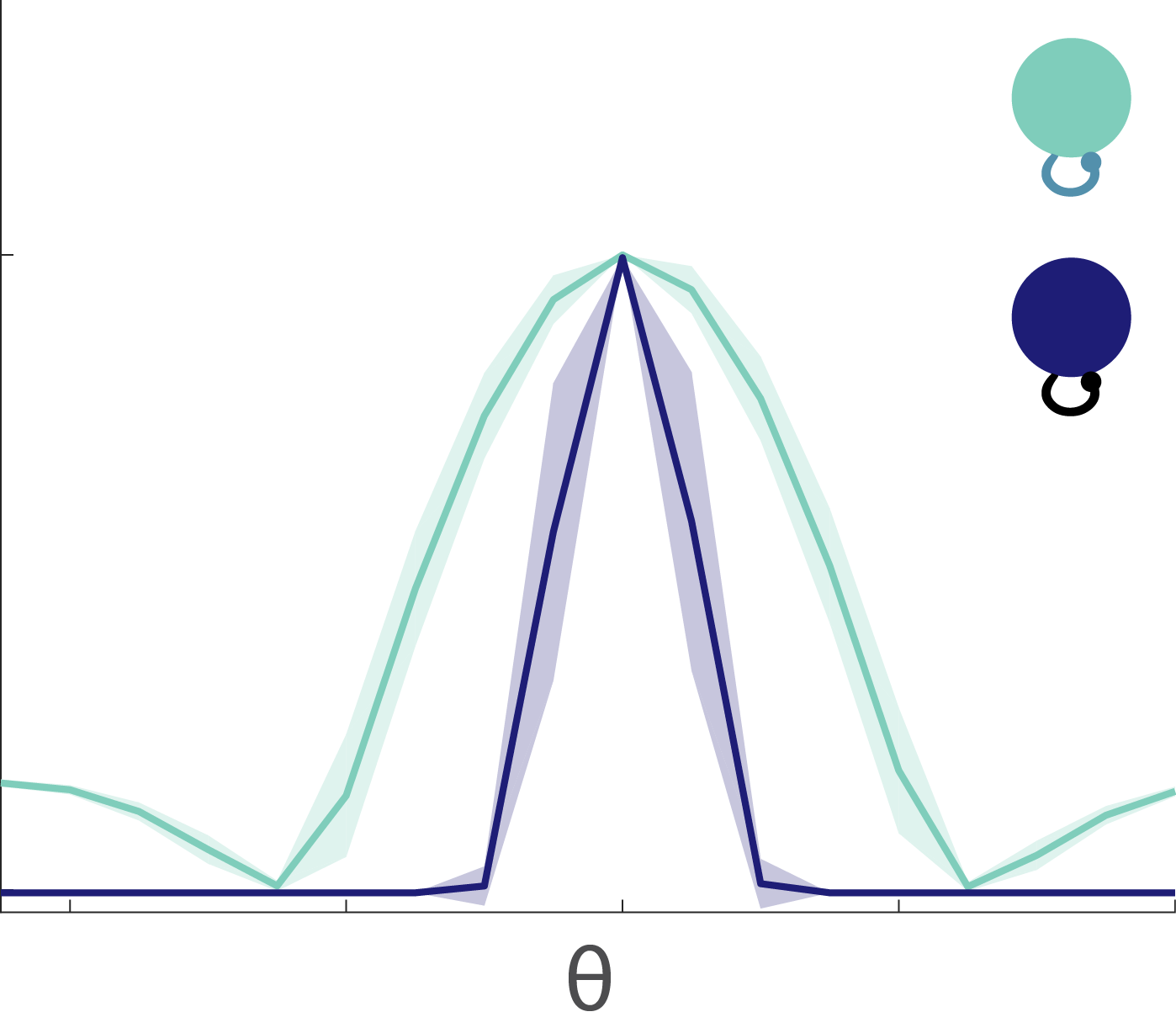
With two subunits, the nonlinear subunits circuit retains more information than the linear subunits circuit, but what happens when there are more than two subunits? The more subunits you compress together, the more difficult it should be to distinguish between different stimuli. Indeed, this is true, but we wondered if the nonlinear subunits circuit would continue to have an advantage over the linear subunits circuit as more subunits are converged. Figure 7 shows that it does. With more subunits, the output response distribution becomes more gaussian, spreading responses out and shifting them towards more positive values (Fig. 7B). The more nonlinear subunits that are converged, the more the nonlinear subunits circuit gains an advantage, up to a saturation point (Fig. 7C). In essence, the convergence of increasing numbers of nonlinear subunits allows the circuit to escape from the compression imposed by the thresholds of the individual nonlinearities themselves.

Figure 7: (A) The output distribution for the linear subunits circuit does not change with more subunits. (B) The output distribution for the nonlinear subunits circuit shifts away from zero and becomes more gaussian. (C) The information entropy for the nonlinear subunits circuit increases with more subunits [subunits undergo an identical normalization regardless of their linearity or nonlinearity].
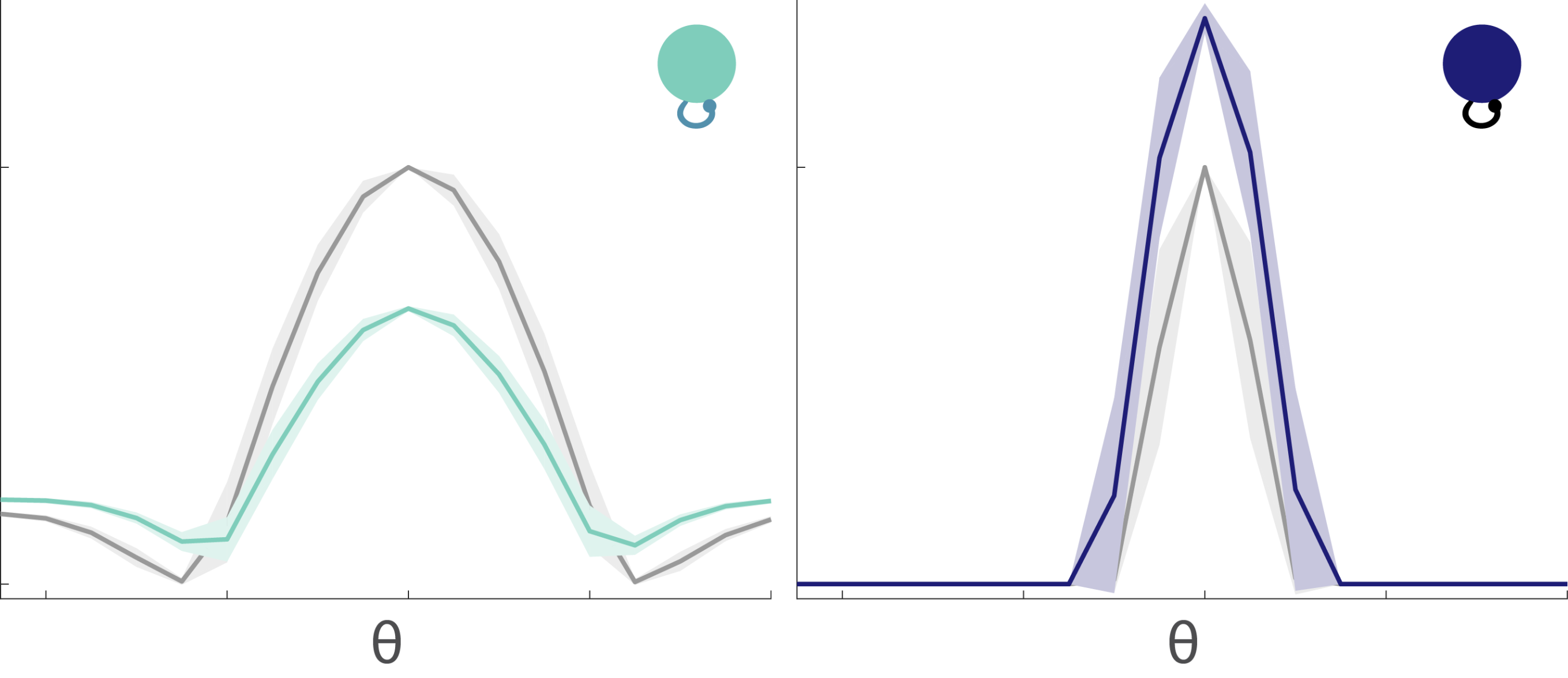
It would seem that this explains it all; however, there is something subtle to consider. In Figure 5, the circuits had two complementary, diverging pathways – an ON and an OFF pathway. You might have expected the divergence to redeem the linear subunits circuit since the OFF pathway can encode all the stimulus information that the ON pathway discarded. So why is the nonlinear subunits circuit still better? The explanation is in Figure 8 which tracks a distribution of 2-dimensional stimuli through circuits with 2 diverging pathways (ON and OFF) and two subunits in each pathway.
The points are all color-coded by the stimulus quadrant they originated from. The linear subunits don’t meaningfully transform the stimuli (Fig. 8A), although the OFF subunit space is rotated because the OFF subunits put a minus sign on the inputs. When the linear subunits are converged within their respective pathways, the ON and OFF responses compress everything onto a diagonal line because they are perfectly anti-correlated (Fig. 8B). When the output nonlinearities are applied, this linear manifold gets folded into an L-shape (Fig. 8C). Notice how the information entropy for the output response of the linear subunits circuit with diverging pathways is higher than it was with just a single pathway (Fig. 7C, black) – but it has only gone up enough to match the information entropy of a single pathway response without any nonlinearities in either the subunits or the output (Fig. 7C, grey dashed). In other words, the OFF pathway in the linear subunits circuit with output nonlinearities (Fig. 8C) is indeed rescuing the information discarded by the ON pathway, but it cannot do any better than an ON pathway with no nonlinearities anywhere. So how is the nonlinear subunits circuit able to preserve even more information?

Figure 8: Geometrical exploration of the compressive transformations that take place in the linear and nonlinear subunits circuits.
Well, first notice how the nonlinear subunits transform the inputs (Fig. 8D). The nonlinearities actually compress the subunit space, but they do so in complementary ways for the ON and OFF subunits. When these subunits are converged in their respective pathways (Fig. 8E), the output response has some similarities to that for the linear subunits circuit (Fig. 8C). The L-shaped manifold is still there, but the orange and purple points have been projected off of it. These points represent the stimulus inputs with mixed sign. By virtue of having these points leave the manifold and fill out the response space, information entropy is increased. In fact, as more nonlinear subunits are converged in a circuit that also has divergence, the information entropy continues to increase until saturation (Fig. 8F). It even increases beyond that of the fully linear response (shown in Fig. 8B) where there are no nonlinearities anywhere.
Manifold-schmanifold. Does the nonlinear subunits circuit encode something meaningful for the retina or what? Figure 9 shows that it does! The nonlinear subunits circuit encodes both mean luminance and local contrast whereas the linear subunits circuit is only able to encode the mean luminance of the stimulus. So the convergence of nonlinear subunits not only preserves more quantifiable information, it also preserves more qualitatively useful stimulus information.

Figure 9: (A) The stimulus space is color-coded by bands of of mean luminance. A banded structure is preserved in the output reponse spaces of both the linear and nonlinear subunits circuits. The red square is a reference point. The cyan square has the same mean as the red square, but a different contrast. The red circle has the same contrast as the red square but a different mean. There is no overlap of these shapes in the response space of the nonlinear subunits circuit. (B) The stimulus space is color-coded by contrast levels. The response space of the linear subunits circuit overlaps these levels, providing no distinction between them. The nonlinear subunits circuit preserves separate contrast bands in its response space.
Taken together, what this means for the retina is that the compression algorithm it uses might also be the same one that maximizes information about the stimulus distribution. This is especially noticeable when we focus on the nonlinearity. Nonlinear transformations can induce selectivity, or they can produce an efficient encoding of the stimulus. We’re not used to thinking of them as doing both at the same time though because an efficient code indicates that information about the stimulus is maximized whereas selective coding means that some information about the stimulus will have to be discarded or minimized. My study suggests that selective coding at the single cell level may be leveraged to efficiently encode as much information about the stimulus as possible at the level of the whole circuit.
* a full manuscript of this work is now on bioRxiv – click here


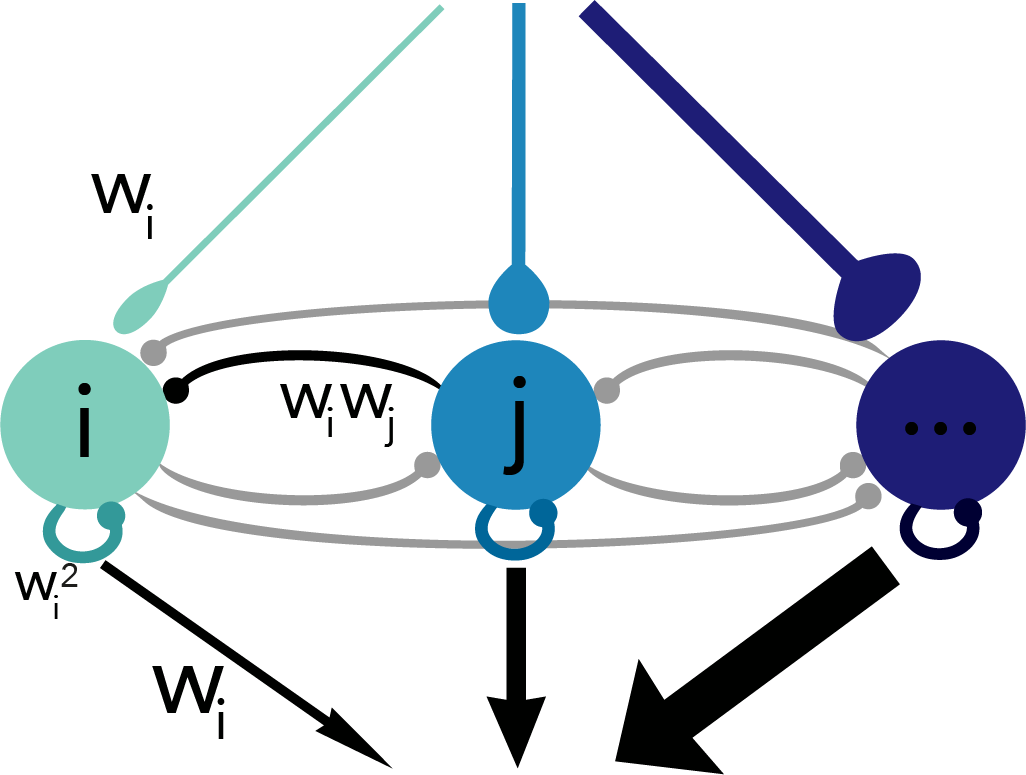
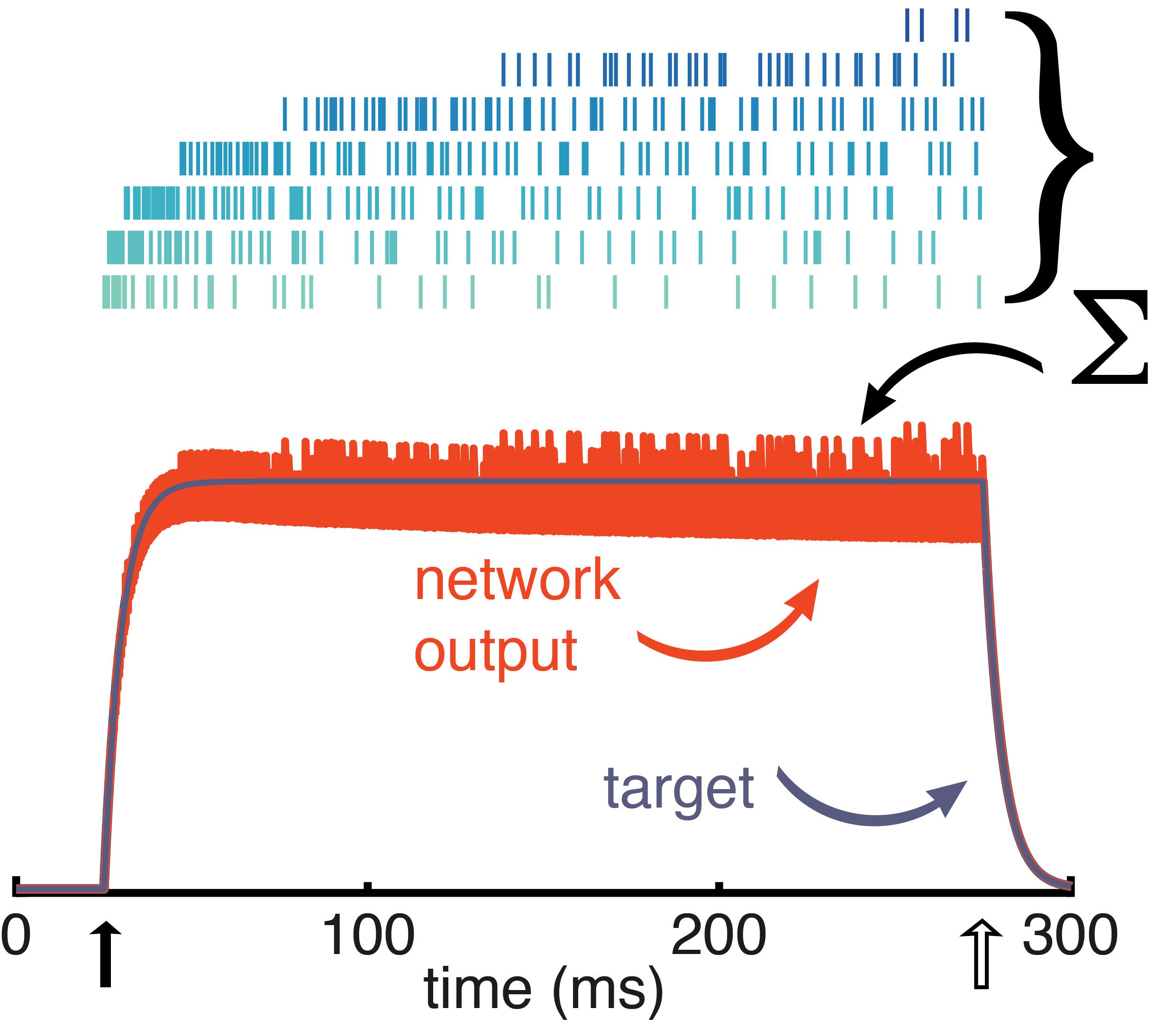
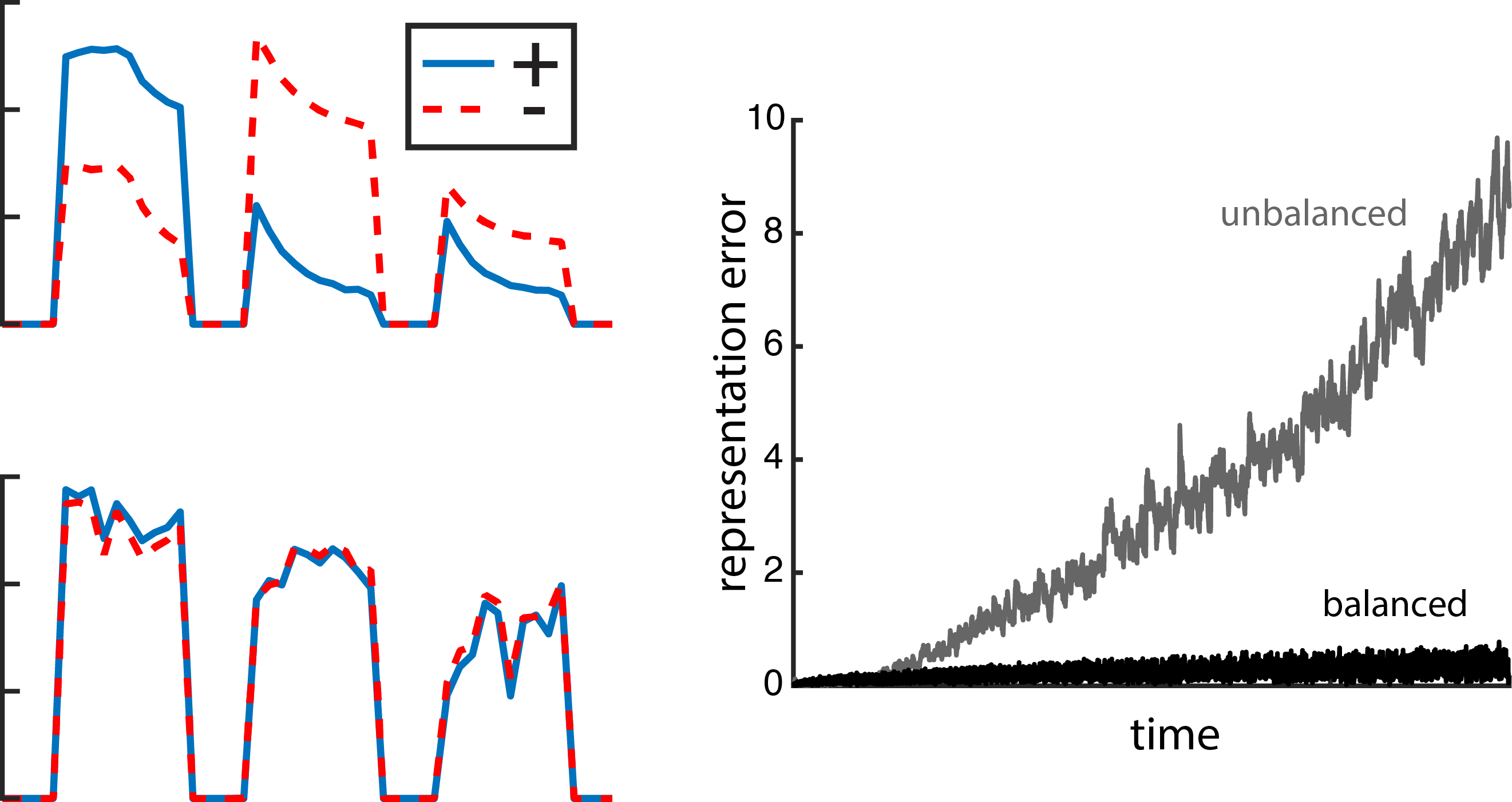
 . The variable, x(t), is called the target signal because it is what we expect the network to produce given the input, but what the network actually puts out is denoted as x̂(t). We assume that the true network output is a linear sum of the activity of the network units,
. The variable, x(t), is called the target signal because it is what we expect the network to produce given the input, but what the network actually puts out is denoted as x̂(t). We assume that the true network output is a linear sum of the activity of the network units, 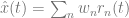 , where ri(t) is the activity of neuron i and wi is its readout weight. It is this actual network output, x̂(t), that will be compared to the target output, x(t).
, where ri(t) is the activity of neuron i and wi is its readout weight. It is this actual network output, x̂(t), that will be compared to the target output, x(t).![E(t) = [x(t) - \hat{x}(t)]^2 + \mu \sum_n r_n(t)^2](https://s0.wp.com/latex.php?latex=E%28t%29+%3D+%5Bx%28t%29+-+%5Chat%7Bx%7D%28t%29%5D%5E2+%2B+%5Cmu+%5Csum_n+r_n%28t%29%5E2&bg=ffffff&fg=656565&s=0&c=20201002)
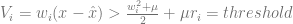 .
.